Books - Read and Enjoyed
Atlas of AI
Kate Crawford
Yale University Press, 2021
This book is not about Artificial Intelligence as a computer science technology, but about its impact in our society. It is meant as a map of AI in our world, but not a geometric map, but rather a map that shows where AI interacts with our physical world and our societies. The book is structured in six main chapters along the main locations of interaction and impact:
-
Resources in terms of minerals and energy: mining and energy consumption,
-
Labor in terms of the human employers and work force that facilitates and sustains AI,
-
Data collected and used for training AI systems,
-
Classification: how AI techniques are used to categorize the world and what impact its way of categorization has on human societies,
-
Affect: how human facial expressions are interpreted by AI systems as emotional states and the impact of this particular way of interpretation on human societies,
-
The state: how the state, together with large corporations, use AI to perceive of and operate in human societies,
-
Power in terms of how AI influences the power systems in our societies.
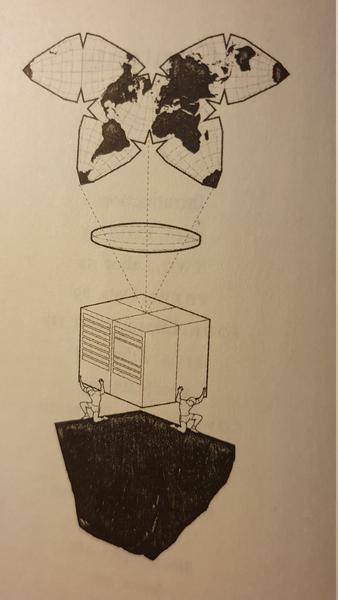
Resources
The book’s thesis is that modern AI technology has a profound impact on human societies and it starts out by illuminating the enormous resources required by the operation of AI systems. Modern computer infrastructure needs almost all elements of the periodic system, some of which are more difficult to extract than others. AI is not alone in using this infrastructure with electrification and digitalization being other major trends. But they all combine in intertwined ways as the transformation of the car industry toward electric and self-driving vehicles illustrates, and AI systems are a rapidly growing consumer of resources. The first chapter explores how the mining of minerals like copper, cobalt, lithium, gold, tin, tungsten, tantalum, neodymium, germanium, etc. pollute the environment and wreck havoc on the local societies and nations where they are extracted. It fuels corruption, nepotism, militarization, conflicts and large scale violence because of the large profits to be extracted together with the minerals.
An even more profound impact of AI on our environment is caused by its energy needs. One example of the energy hunger of AI is found in a paper by Emma Strubell et al. from 2019. It compares a single machine learning system with an average US car and found that the carbon footprint of training of that system is about 284 tons of carbon dioxide, which corresponds to the footprint of five average cars during their lifetime including manufacturing and fuel consumption. As a reference, the footprint of 1 ton CO2 per person per year is considered to be climate neutral; the average European produces 6.5 ton CO2/year. The machine learning system studied by Strubell and her colleagues is a natural language transformer model, no unlike to ChatGPT, which has made furor last year. Belonging to a more recent generation of language models, ChatGPT produced almost certainly many times as much CO2 of the above figure for training, not to speak of its footprint during operation, when we all use it. Machine learning systems are incredibly power hungry with a steep, exponential upwards trend. There are estimates that by 2040 the total ICT infrastructure will contribute as much as 14% to the worlds total carbon footprint, which means it becomes a major contributing sector, like traffic and agriculture. AI is not the only user of ICT infrastructure but a significant one and growing quickly.
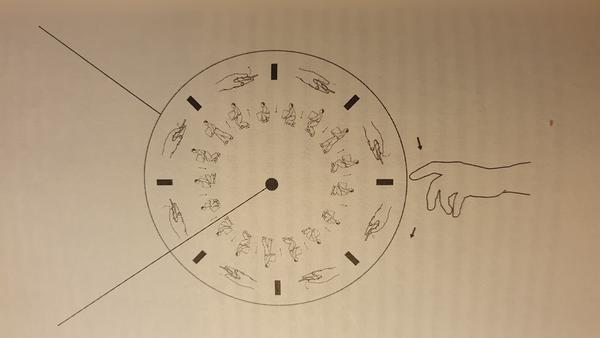
Labor
The next chapter of the book, on labor, illuminates the curious fact that an army of cheap laborers is required to facilitate the wonders of modern AI systems. One of the most fascinating success stories of AI in the last ten years is object recognition in images. The recent hype in Deep Neural Networks (DNN) started in 2012 with AlexNet when it blew away the competition in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). AlexNet has been developed by Alex Krizhevsky and published with Ilya Sutskever and Geoffrey Hinton, from the University of Toronto. It is the root of a class of Convolutional Neural Networks that has since then experienced a Cambrian explosion resulting in a huge diversity of networks that vastly vary in size, shape and complexity, and have since been applied to all possible applications.
Today these DNNs can identify objects in images with speed, precision and reliability that outperform humans. However, they are machine learning algorithms and have to be trained with a very large data set. The instructions for the 2012 LSVRC competition read:
The validation and test data for this competition will consist of
150,000 photographs, collected from flickr and other search
engines, hand labeled with the presence or absence of 1000 object
categories. The 1000 object categories contain both internal nodes
and leaf nodes of ImageNet, but do not overlap with each other. A
random subset of 50,000 of the images with labels will be released
as validation data included in the development kit along with a
list of the 1000 categories. The remaining images will be used for
evaluation and will be released without labels at test time.
The training data, the subset of ImageNet containing the 1000
categories and 1.2 million images, will be packaged for easy
downloading. The validation and test data for this competition are
not contained in the ImageNet training data (we will remove any
duplicates).
The training set consists of 1.2 million images that have been labeled, which means that the object to be identified is marked with a rectangular bounding box. Who has done the labeling? It was mostly done by an internet service called the Amazon Mechanical Turk. There everyone with Internet access can offer their service to do all kinds of tasks like labeling images. Due to a fierce worldwide competition the labor cost per hour is driven very low.
ImageNet would become, for a time, the world's largest academic
user of Amazon's Mechanical Turk, deploying an army of piecemeal
workers to sort an average of fifty images a minute into thousands
of categories.
(p 108)
Up to today, obtaining large amounts of high quality training data is a central challenge for most machine learning applications, and it is usually solved by employing an army of human laborers for rock bottom salaries.
It is indeed a general phenomenon that AI systems only work well when complemented by human laborers. Object recognition software works sublimely well when it has access to data labeled by humans. Amazon logistic centers are automated to a very high degree full with sophisticated software for scheduling boxes, selecting items, continuously optimizing the deployment of material and workers, but certain tasks like filling boxes with delivery items are best done by humans. Automatic driving software is amazingly effective most of the time but requires a human to take over when something unexpected happens or some unforeseen situation emerges. So while AI can take over many tasks that were reserved for humans until recently, it is often not sufficiently adaptable or has the necessary insight to deal with corner cases or unexpected situations. And those tasks left for humans are sometimes appealing but very often they are mundane, tiring and lowly paid. In particular in the logistics and manufacturing industries the processes are often optimized for machines and steered by sophisticated algorithms with some tasks left for humans who have to adapt to the overall machinery. Because humans are so amazingly adaptable, can deal with all kinds of unexpected situation, and, after some time, become highly efficient at whatever task is thrown at them, they are assigned to the activities at which machines and AI still fall short. More often than not, these activities are poorly paid because they do not require a long education like filling boxes, carrying bags over staircases to the third floor, cleaning rooms full with random objects and materials, etc. This is probably the result of a combination of two facts: First, humans are optimized by evolution for tasks to navigate and manipulate a very complex physical environment. These tasks appear cognitively undemanding because our bodies and brains are so good at it that they require almost no conscious effort. But in reality these tasks are very difficult and AI is not yet sufficiently sophisticated and mature to handle them. Second, because the relevant faculties are innate to humans, everybody can do it without long or special education. Thus, as long as there is a supply of uneducated labor, salaries are driven to the bottom.
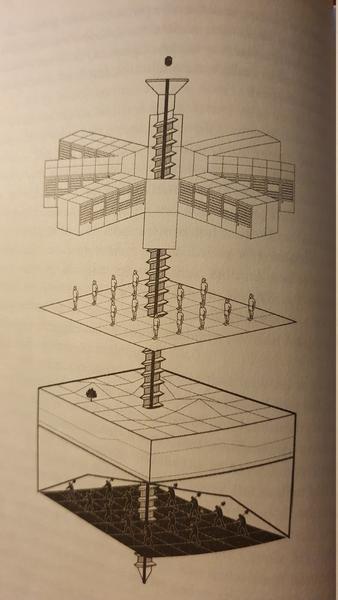
Categorization
The chapters on data, categorization and affect address a particularly uncanny aspect of modern AI: Machine learning algorithms do not work like human brains. They perceive the world distinctly different. This is exemplified by categorization tasks, and object identification in images is one specific categorization task. The COMPAS software, that I have previously discussed in the review of “We, the Robots”, is a case in point. COMPAS, short for Correctional Offender Management Profiling for Alternative Sanctions, is a popular software used in US courts for assessing criminal offenders. Trained with data from a database of criminal offenders COMPAS generates a score from 1 to 10 to indicate the estimated probability for future commitment of crimes. It is used regularly in criminal cases to assess the likelihood of future offenses of current criminal offenders. The software is trained on whatever data is available on the hard disk that stores the digitized records of past offenses. It does not perceive people as people, it does not understand feelings like shame and hate, desire for appreciation and power, pride, aspirations and loneliness. It does not understand the context of families and friends, social networks and social expectations. Human officers and judges can take all these aspects into account when looking at a criminal offender, but COMPAS does not do that and has therefore a radically different perception of people it assesses. Machine learning algorithms are deeply biased by the data they are trained with and by the implicit set of assumptions underlying their architecture.
In the chapter on affect Crawford illustrates this aspect with software that reads the emotions of people based on their facial expressions. The promise of such systems is to be able to detect when people lie, plan terrorist attacks, or have special psychiatric conditions. They are therefore demanded and promoted by security agencies and police in many countries, democratic and authoritarian. However, it is very curious that, despite the high expectations in such systems and their real-life deployment, there is no good scientific basis and no sufficient evidence that these systems can actually work. The underlying assumption of affect recognition systems is that emotional states can reliably be inferred from facial expressions. However, that seems to be shaky assumption.
In 2019, Lisa Feldman Barret led a research team that conducted a
wide-ranging review of the literature on interfering emotions from
facial expressions. They concluded firmly that facial expressions
are far from indisputable and are "not 'fingerprints' or
diagnostic displays" that reliably signal emotianal states, let
alone across cultures and contexts. based on all the current
evidence, the team observed, "It is not possible to confidently
infer happiness from a smile, anger from a scowl, or sadness from
a frown, as much of current technology tries to do when they are
applying what they mistakingly believed to be scientific facts."
(p 174)
So given this lack of clear evidence, that emotional states can be reliably inferred from the expression of a face, what can we expect from machine learning software that is deployed in job interviews, criminal investigations or counter terrorist operations to do exactly this? I am afraid we have to expect a lot of bad judgment with often dire consequences.
Today, AI is charged with categorization tasks in a wide range of applications by state actors, corporations and individuals. Emails are categorized into spam or no-spam, news are categorized into worthy of of communicating or not, job applicants are categorized into being worth to be invited for an interview or not, criminal offenders are being categorized into being a future threat or not, travelers are categorized to be a potential security threat or not, loan applications are being categorized into high risk or low risk. Categorization is not the same as decision making, and in most of these applications important decisions are still made by humans who consider the software to be a useful tool. And very often it is a useful tool, but its usefulness depends on two assumptions: first, the human decision maker understands the bias, hidden assumptions and limitations of these tools. Second, the human decision maker takes into account all the aspects not considered by the tool and factors both these other aspects and the tool’s limitations into the decision making process. Already today it is a safe assumption that these two conditions are rarely met and as AI technology advances, the categorization tools become more and more the decision makers. Since their perception of the world and of humans and human societies are distinctively non-human, this development will have dire consequences.
Power
In the final chapters Crawford discusses the impact of AI on the operation of states and corporations and on the power distribution. Her conclusions are as clear as they are depressing. The effect of AI is a massive increase of inequality and imbalance of power. Individuals, organizations and states who are powerful today will become more powerful in the future, because AI is (a) an exceedingly effective and general tool for all manners of monitoring, surveillance and control, and (b) it is increasingly expensive to acquire and deploy. Thus AI turns out to be a great amplifier of power differentials.
(AJ February 2023)
